In this post, we will scale a Kubernetes based deployment of Elasticsearch:
1.) by growing a 3-node ES cluster to a 5-node ES cluster i.e. horizontal scaling and,
2.) by changing the underlying instance types of each node, i.e. vertical scaling.
1.) by growing a 3-node ES cluster to a 5-node ES cluster i.e. horizontal scaling and,
2.) by changing the underlying instance types of each node, i.e. vertical scaling.
If you are new to the idea of Kubernetes aka K8S as a deployment tool, I highly recommend checking out my earlier post where I show how to go from zero to a persistent Elasticsearch DB deployment in 10 steps.
We will be using the above post as a baseline to talk about scaling, I will wait here while you read it ☺
Quick Recap
Here’s a quick tl;dr recap: In the previous post, we start out by creating a 3-node K8S cluster and set up a 3-node ES deployment using the following two commands:
# I am assuming that you already have a K8S cluster setup. If not, go read this post on setting one up: https://medium.appbase.io/deploy-elasticsearch-with-kubernetes-on-aws-in-10-steps-7913b607abda# Start with deploying ES via statefulset and persistent volumes kubectl create -f https://raw.githubusercontent.com/raazcrzy/kubernetes/master/elasticsearch/elasticsearch-statefulset.yaml# Finally, create a loadbalancer service to expose the ES cluster kubectl create -f https://raw.githubusercontent.com/raazcrzy/kubernetes/master/elasticsearch/elasticsearch-loadbalancer.yaml
You can check on the status of the deployment with the following command:
kubectl get all[ec2-user@ip-172-31-35-145 test]$ kubectl get all NAME DESIRED CURRENT AGE statefulsets/es 3 3 2hNAME READY STATUS RESTARTS AGE po/es-0 1/1 Running 0 45m po/es-1 1/1 Running 0 45m po/es-2 1/1 Running 0 44mNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 100.67.33.11 ac3e3c16f214e... 9200:31243/TCP,9300:31744/TCP 2d svc/kubernetes ClusterIP 100.64.0.1 <none> 443/TCP 2d
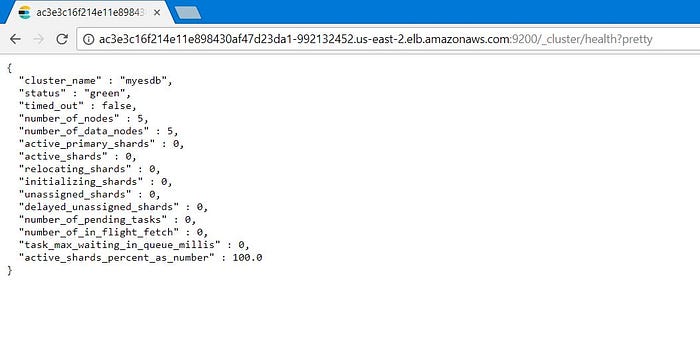
And finally, you can also check the health of the ES cluster with the following request in a browser:
http://<elasticsearch-service-external-ip>:9200/_cluster/health?prettyScaling Elasticsearch
Elasticsearch is a distributed search engine that is designed for high availability. In this post, we will look at two common operations with K8S that you will need to perform in a production deployment.
- Scaling of nodes with almost zero downtime. Elasticsearch throughput scales horizontally, so this is a very common operation to scale up / down ES throughput based on production requirements.
- Changing the underlying hardware or migrating your ES deployment from one IaaS provider to another or a bare-metal system.
To prevent any data loss while scaling out, I also recommend ensuring the following two things:
- Each Elasticsearch container pod should run on at least and at most one K8S agent node — this is to preserve the HA guarantees of Elasticsearch.
- All Elasticsearch indices should have at least one replica. This ensures that at least one copy of a shard is present in the cluster during rolling upgrades, thus minimizing .
Finally, if you are doing this on a production cluster, I recommend taking a snapshot and backing it up externally (like AWS S3) before starting out.


Growing a 3-Node ES Cluster to a 5-Node Cluster
Before we get started, let’s recap how a K8S cluster works. Before we set out to grow our ES cluster to 5 nodes, we should ensure that our K8S cluster has 5 nodes, otherwise more than one pod will get scheduled on the same node which is not desired if we want high availability.
Since we started with only 3 nodes for our K8S cluster, we need to first scale the K8S agent nodes to 5 and then scale our ES nodes.


Kops has the concept of “instance groups”, which are a group of similar machines. To scale the nodes, we need to fetch the instance group name to which our nodes belong and then increase the number of nodes in the group. Lets first get the list of instance groups present in our cluster.
The following command will list down the instance groups of your cluster.
[ec2-user@ip-172-31-35-145 examples]$ kops get ig Using cluster from kubectl context: k8s.appbaseNAME ROLE MACHINETYPE MIN MAX ZONES masters Master t2.large 1 1 us-east-2c nodes Node t2.medium 3 3 us-east-2c
1. Run the following command to edit instance group configuration for the agent nodes. Replace <nodes> with your instance group name.
kops edit ig <nodes>
You should see a config file open.
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: 2018-02-14T12:26:43Z
labels:
kops.k8s.io/cluster: k8s.appbase
name: nodes
spec:
image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14
machineType: t2.medium
maxSize: 3
minSize: 3
nodeLabels:
kops.k8s.io/instancegroup: nodes
role: Node
subnets:
- us-east-2c
In order to scale the nodes we need to edit minSize and maxSize in the config file of the instance group to which our agent nodes belong. The maxSize defines the maximum number of nodes we want up at any given time while minSize defines the minimum number of nodes that must be up at any given time.
2. Here, we will change the
maxSize and minSize values to 5.apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: 2018-02-14T12:26:43Z
labels:
kops.k8s.io/cluster: k8s.appbase
name: nodes
spec:
image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14
machineType: t2.medium
maxSize: 5
minSize: 5
nodeLabels:
kops.k8s.io/instancegroup: nodes
role: Node
subnets:
- us-east-2c
3. Next, we need to update the cluster to apply the configuration change we just made.
kops update cluster --yes
kops rolling-update cluster
It may take few minutes to add the nodes as new VMs will be added to the cluster. You can verify the new node count by getting the nodes of the cluster.
4. Run:
kubectl get nodesNAME STATUS ROLES AGE VERSION
ip-172-20-44-33.us-east-2.compute.internal Ready master 12h v1.8.6
ip-172-20-52-48.us-east-2.compute.internal Ready node 2d v1.8.6
ip-172-20-62-30.us-east-2.compute.internal Ready node 2d v1.8.6
ip-172-20-64-53.us-east-2.compute.internal Ready node 2d v1.8.6
ip-172-20-67-30.us-east-2.compute.internal Ready node 1m v1.8.6
ip-172-20-87-68.us-east-2.compute.internal Ready node 1m v1.8.6
As you can see, we now have a K8S cluster of 5 agent nodes.
Now let’s scale the Elasticsearch nodes from 3 → 5.

We can scale Elasticsearch horizontally by simply specifying the number of replicas. This method can be used for both — scaling up as well as scaling down.
kubectl scale --replicas=5 statefulset es
You can adjust the number of replicas to suite your need (make sure you have enough nodes for the replicas).
[ec2-user@ip-172-31-35-145 ~]$ kubectl scale --replicas=5 statefulset es
statefulset "es" scaled
You can verify the number of Elasticsearch pods and the nodes on which they are running by the following command:
kubectl get pods -o wide
You should get a table of your pods along with the nodes on which they are deployed.
When you hit the URL of Elasticsearch to check the health of your nodes, you should now notice the number of Elasticsearch nodes increase to five.

Vertical scaling of Elasticsearch nodes

Scaling Elasticsearch vertically means we are going to let our ES nodes use more/less memory, disk and computing resources. In order to achieve this, we need to vertically scale our K8S node by changing the instance type of the node VM to suit our need and then editing the JAVA_HEAP_SIZE and number of CPU of the Elasticsearch statefulset resource that we deployed on K8S. The statefulset will update the Elasticsearch to use the updated resource limits.


We start by vertically scaling the K8S nodes. The process is similar to horizontally-scaling K8S nodes.
- Get the instance group name of nodes.
Run:kops get ig - Edit the config of instance group for the nodes.
Run:kops edit ig <ig name> - Change the type of machine
machineTypeto whichever machine you want to scale up. Make sure that machine type is available in the AZ you have provisioned the cluster. We have our nodes provisioned witht2.mediumVMs. Change it tot2.large. - Save the file and update the cluster.
kops update cluster --yes
kops rolling-update cluster
Wait for few minutes untill all your ec2 instances are terminated and new machines come up. Then check the validity of cluster.
5. Run:
kops validate cluster
It should show you the cluster with new machine types:
[ec2-user@ip-172-31-35-145 examples]$ kops validate cluster Using cluster from kubectl context: k8s.appbaseValidating cluster k8s.appbaseINSTANCE GROUPS NAME ROLE MACHINETYPE MIN MAX SUBNETS masters Master t2.large 1 1 us-east-2c nodes Node t2.large 5 5 us-east-2cNODE STATUS NAME ROLE READY ip-172-20-44-33.us-east-2.compute.internal master True ip-172-20-52-48.us-east-2.compute.internal node True ip-172-20-62-30.us-east-2.compute.internal node True ip-172-20-64-53.us-east-2.compute.internal node True ip-172-20-67-30.us-east-2.compute.internal node True ip-172-20-87-68.us-east-2.compute.internal node True
We have just scaled our K8S nodes vertically.
Next, we can scale our ES nodes vertically. For this, we need to update the Elasticsearch statefulset.
kubectl edit statefulset es
Now edit the value of
JAVA_HEAP_SIZE in the list of environment variables from -Xms256m -Xms256m to -Xms1g -Xms1g .
Elasticsearch settings defaults to use total number of available processors. Since instance type t2.large has 2 processors, ES nodes will use all 2 processors.
After saving the file, the statefulSet should upgrade the ES nodes with the updated configurations and our ES cluster will scale up vertically. To verify the vertical scaling, you can check the ES
_nodes API endpoint by hitting the Elasticsearch cluster’s URL.http://<external address>:9200/_nodes/os,jvm?pretty

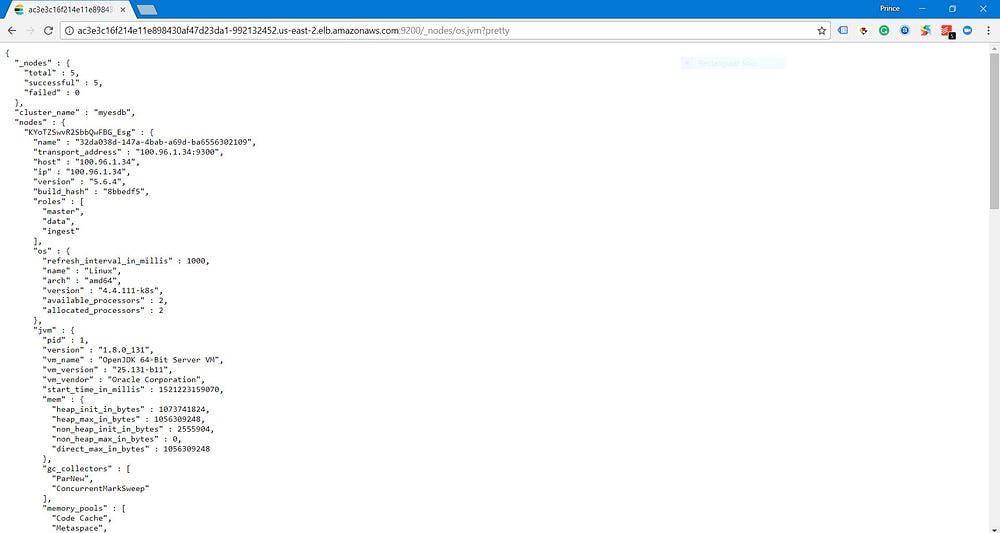
Look at the available_processors and allocated_processors under os, it should be 2. And the heap_init_in_bytes under jvm should be approximately equal to 1 GB.
{
"_nodes" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"cluster_name" : "myesdb",
"nodes" : {
"tYujtUCNTuOYlXDDMG4Fbg" : {
"name" : "6fe0014d-561d-4457-ba1a-4d287b812f80",
"transport_address" : "100.96.2.34:9300",
"host" : "100.96.2.34",
"ip" : "100.96.2.34",
"version" : "5.6.4",
"build_hash" : "8bbedf5",
"roles" : [
"master",
"data",
"ingest"
],
"os" : {
"refresh_interval_in_millis" : 1000,
"name" : "Linux",
"arch" : "amd64",
"version" : "4.4.111-k8s",
"available_processors" : 2,
"allocated_processors" : 2
}
},
"jvm" : {
"pid" : 1,
"version" : "1.8.0_131",
"vm_name" : "OpenJDK 64-Bit Server VM",
"vm_version" : "25.131-b11",
"vm_vendor" : "Oracle Corporation",
"start_time_in_millis" : 1521222438059,
"mem" : {
"heap_init_in_bytes" : 1073741824,
"heap_max_in_bytes" : 1056309248,
"non_heap_init_in_bytes" : 2555904,
"non_heap_max_in_bytes" : 0,
"direct_max_in_bytes" : 1056309248
},
"gc_collectors" : [
"ParNew",
"ConcurrentMarkSweep"
],
"memory_pools" : [
"Code Cache",
"Metaspace",
"Compressed Class Space",
"Par Eden Space",
"Par Survivor Space",
"CMS Old Gen"
],
"using_compressed_ordinary_object_pointers" : "true",
"input_arguments" : [
"-XX:+UseConcMarkSweepGC",
"-XX:CMSInitiatingOccupancyFraction=75",
"-XX:+UseCMSInitiatingOccupancyOnly",
"-XX:+DisableExplicitGC",
"-XX:+AlwaysPreTouch",
"-Xss1m",
"-Djava.awt.headless=true",
"-Dfile.encoding=UTF-8",
"-Djna.nosys=true",
"-Djdk.io.permissionsUseCanonicalPath=true",
"-Dio.netty.noUnsafe=true",
"-Dio.netty.noKeySetOptimization=true",
"-Dlog4j.shutdownHookEnabled=false",
"-Dlog4j2.disable.jmx=true",
"-Dlog4j.skipJansi=true",
"-XX:+HeapDumpOnOutOfMemoryError",
"-Xms1g",
"-Xmx1g",
"-Des.path.home=/elasticsearch"
]
}
},
...
Conclusion
We walked through two strategies of scaling an Elasticsearch cluster: 1.) Horizontal Scaling and 2.) Vertical Scaling. We use Kops’s instance groups functionality to declaratively update the K8S nodes first and then make a similar change in the statefulset deployment of Elasticsearch.
While the blog post has only focused on Kops / AWS, a similar setup is possible in a K8S cluster hosted anywhere.
If you are still new to idea of deploying a distributed system like Elasticsearch with Kubernetes, I recommend reading on my earlier blog post.


